

Working with Collections as Data
The Centre for Digital Scholarship has been involved in project that aimed to explore the various ways in which digital heritage collections can be analysed using data science methods.
During the past few decades, many libraries, museums, and archival institutions have been in the process of digitising their collections. More and more GLAM institutions additionally share the data that result from such wide-ranging digitization efforts directly, in raw machine-readable formats and under open licences. Combined with the growing sophistication of data science methods, this abundance of data about cultural objects clearly opens up new and interesting possibilities.
The project “Connecting to the Network of Cultural Heritage” was initiated at Leiden University to encourage students and researchers to engage with the digital collections made available by heritage institutions. This project was funded by ECOLE and by CLARIAH plus. The project was led by Peter Verhaar and Karin de Wild.
One of the project’s central results was a series of tutorials explaining the use and the creation of Linked Open Data (LOD), a method for publishing structured data via the web. The educational resources that were developed are targeted towards learners without any prior knowledge about LOD. The tutorial explains basic topics such as the RDF data model, the concept of vocabularies and the SPARQL Query language. Additionally, the tutorial also explains the steps that can be followed to create LOD out of, for example, a CSV file. The tutorial also discusses some of the tools that can be used in this context, such as the LDWizard and the CLARIAH Data Legend tools GRLC and CoW.
Following the examples set by the GLAM Workbenches initiative, the project also developed a series of interactive Jupyter notebooks to clarify the kinds of research questions that can be addressed using computational analyses of digital heritage collections. These interactive notebooks all contain code snippets, data visualisations and explanations of methods. They were developed to enable teachers and researchers to develop a better understanding of the methods associated with data science, and also to stimulate them to think about relevant applications of such methods within humanities research.
The work in this project was strongly informed by some of the recent publications on the concept of collections as data. In the final report of the Always Already Computational project (Padilla et al., 2019), the concept of Collections as Data is described as “a conceptual orientation to collections that renders them as ordered information, stored digitally, that are inherently amenable to computation” (p. 7). Within the DARIAH programme, a position paper was also published which similarly stressed that “cultural heritage data is humanities research data” (pp. 1-2), and that the data should therefore be made available, insofar as possible, as findable, accessible, interoperable and reusable datasets (Tasovac et al., 2020). Many libraries, such as National Library of the Netherlands and the British Library have established data labs and data foundries which enable researchers to download large volumes of data that can used in studies based on methods and techniques such as text mining, machine learning and network analysis. The project “Connecting to the Network of Cultural Heritage” was essentially initiated to make it easier for students and for researchers to interact with digital collections and to seize the potential offered by such online resources.
One of the interactive notebooks that was developed focuses on the use of the data aggregated by Europeana. This notebook explains the Europeana data model, and discusses the structure of the queries that can be formulated on the Europeana SPARQL endpoint. The notebook contains queries that can retrieve specific types of objects, both within and across heritage institutions. Examples of such object types may include scrapbooks, easel paintings or palm leaf manuscripts. Using Iconclass identifiers, it is also possible to search for works of art in the Europeama database depicting specific types of scenes, such as city panoramas or people reading the Bible.
In the project, a notebook was also developed to showcase the scholarly potential of the digitised medieval books that have been added to Europeana as part of a project named The Art of Reading in the Middle Ages (ARMA). In this project, a group of eight European libraries have uploaded about 65,000 metadata records about medieval manuscripts to the Europeana portal. The metadata about these manuscripts can now be obtained and analysed via Europeana’s SPARQL endpoint and through Europeana’s Search API.
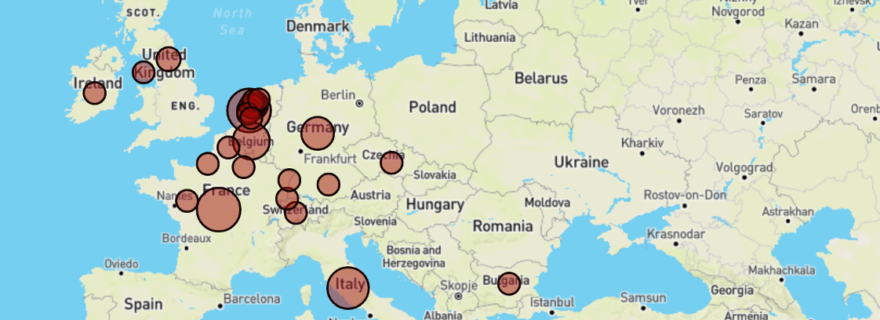
The notebook on ARMA firstly visualises the locations on which these manuscripts were produced via a map.
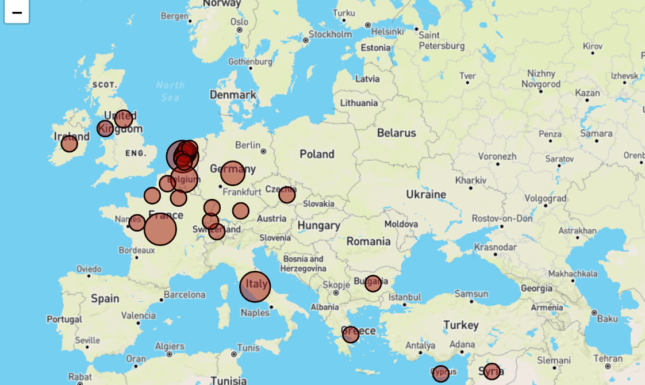
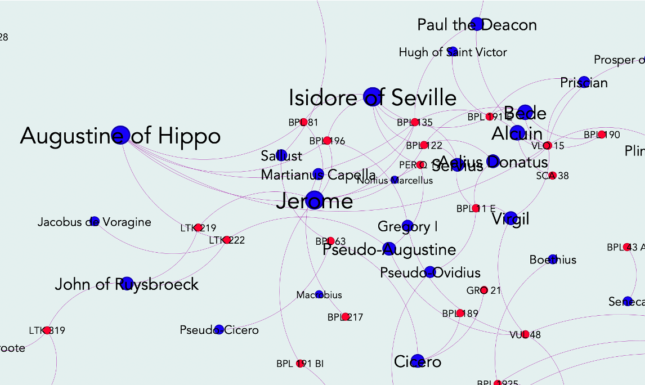
The data made available on Europeana also includes information about the authors of the texts of the manuscripts. On the basis of these author names, it is possible to make a network visualisation showing connections between authors and texts. Graphs such as these can be used to examine the dominance and the authority of particular authors during the Middle Ages. The image below shows a section of the network graph made for Leiden’s ARMA manuscripts. As can be seen, names such as Augustine of Hippo and Isidore of Seville appear quite prominently in this collection.
The metadata that can be extracted from Europeana also includes links to the IIIF manifests, containing the URLs of all the images of the individual pages. These images can also be analysed computationally. It can be interesting, for example, to study the use of rubrication, the addition of text in red ink to a manuscript for emphasis. Using OpenCV in Python, it is possible to select only the pixels containing a shade of red and to make all the other pixels black. Using this method, all the pages containing rubrication can quickly be identified.

During the last two years, the tutorials and the notebooks that were created in the project have been used in MA courses and at coding literacy workshops at Leiden Univerity’s Humanities faculty. In the coming years, these tutorials and interactive Jupiter notebooks will still be developed further, in collaboration with students and researchers in Leiden, but also in close collaboration with national and international partners.